Generating Anki decks with audio from the Tatoeba Project
If you look for the precompiled decks, here is a list.
A Hebrew version of this page is available here.
1. Background
The most effective Anki decks I know for language acquisition share three features:
- They include sentences, as opposed to vocabulary items without co-text.
- All of these sentences have audio recorded by native speakers.
- They are incrementally sorted, meaning that ideally in each sentence you learn no more than one new word or grammatical feature. This idea is also called ‘the i+1 principle’.
The Tatoeba Project has millions of sentences, many of which were recorded by native speakers. As far as I am aware, there are no pre-made tools for importing Tatoeba sentences with audio to Anki, so I made such a tool and created decks for all of the languages that have recordings, incrementally sorted using the MorphMan addon. In order to save you the trouble of creating the decks on your own, I’ve already compiled decks for all of the languages that have audio sentences in Tatoeba.
Tatoeba is an amazing public and open collaborative project, but as all such projects it is not free of mistakes and low-quality entries. The volunteers do their best to minimize them, but they still exists. Having an audio recording can be seen as a filter for better quality sentences: if someone took their time to record a sentence, it is presumably of good quality.
2. Deck generation process
I made the decks on a Linux machine, but I guess you could do the same on macOS or Windows (with Cygwin or something similar). The tools we will use are: sh, Wget, tar, bzip2, sed, uniq, SQLite and Python.
If for some reason the pre-made decks do not suit your needs, don’t hesitate to contact me if you need help with generating a deck the do.
2.1. Downloading the data
Tatoeba exports its data as downloadable CSV files. The files we need are: sentences.csv, links.csv, tags.csv and sentences_with_audio.csv:
We can download, unpack and prepare them for later use by running this script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | #!/usr/bin/sh mkdir -p csv pushd csv # Download wget https://downloads.tatoeba.org/exports/sentences.tar.bz2 wget https://downloads.tatoeba.org/exports/links.tar.bz2 wget https://downloads.tatoeba.org/exports/tags.tar.bz2 wget https://downloads.tatoeba.org/exports/sentences_with_audio.tar.bz2 # Decompress and untar for f in *.tar.bz2; do tar jxf $f done # Prepare sed 's/"/""/g;s/[^\t]*/"&"/g' sentences.csv > sentences.escaped_quotes.csv sed 's/"/""/g;s/[^\t]*/"&"/g' tags.csv > tags.escaped_quotes.csv uniq sentences_with_audio.csv > sentences_with_audio.uniq.csv # Remove compressed files rm -i {sentences, links, tags, sentences_with_audio}.tar.bz popd |
2.2. Making a local database
Now we want to make a database so we will be able to run queries. I chose SQLite because it is local, fast, convenient and easy to setup. By running this SQL file (sqlite3 -init create_db.sql) we create a database with the tables we need and import the data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | .open tatoeba.sqlite3 -- Tatoeba’s database has many deleted entries in `sentences` which are referenced from `sentences_with_audio` and `links`; expect tons of warning messages PRAGMA foreign_keys = ON; CREATE TABLE sentences ( sentence_id INTEGER PRIMARY KEY, lang TEXT, text TEXT ); CREATE TABLE sentences_with_audio ( sentence_id INTEGER PRIMARY KEY, username TEXT, license TEXT, attribution_url TEXT, FOREIGN KEY (sentence_id) REFERENCES sentences(sentence_id) ); CREATE TABLE links ( sentence_id INTEGER, translation_id INTEGER, FOREIGN KEY (sentence_id) REFERENCES sentences(sentence_id), FOREIGN KEY (translation_id) REFERENCES sentences(sentence_id) ); CREATE TABLE tags ( sentence_id INTEGER, tag_name TEXT, FOREIGN KEY (sentence_id) REFERENCES sentences(sentence_id) ); CREATE INDEX links_index ON links(sentence_id, translation_id); CREATE INDEX tags_index ON tags(sentence_id, tag_name); .separator "\t" .import csv/sentences.escaped_quotes.csv sentences .import csv/sentences_with_audio.uniq.csv sentences_with_audio .import csv/links.csv links .import csv/tags.escaped_quotes.csv tags |
The CSV files has many references to deleted sentences, so many warnings will be shown.
2.3. Writing the main query
Now we want to write a query that will output an Anki-importable file with this data in each row:
- Tatoeba sentence ID.
- The text of the sentence in the target language.
- Reference to the audio file.
- Tatoeba tags (such as
colloquial). - Translations of the sentence to languages we already know.
For this purpose I wrote this patchy Python script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | #!/usr/bin/env python3 import argparse import csv import os import sqlite3 output_dir = 'output' native_langs = [] def native_lang_columns(): def native_lang_column(lang): return f""" "<ul class=""translations""><li>" || ( SELECT group_concat(sentences.text, "</li><li>") FROM links JOIN sentences ON links.translation_id = sentences.sentence_id WHERE links.sentence_id = target_sentences.sentence_id AND sentences.lang = '{lang}' ) || "</li></ul>" """ result = "" for lang in native_langs[:-1]: result += native_lang_column(lang) + ", " result += native_lang_column(native_langs[-1]) return result def main(): parser = argparse.ArgumentParser( description="Make a CSV files of sentences from the Tatoeba Project that have audio, along with their translations into selected languages") parser.add_argument("-t", "--target", type=str, help="target language", required=True) parser.add_argument("-n", "--native", type=str, help="native languages (space-delimited, within quotes)", required=True) parser.add_argument("-d", "--database", type=str, help="database file", default = "tatoeba.sqlite3") args = parser.parse_args() global native_langs native_langs = args.native.split(" ") conn = sqlite3.connect(args.database) c = conn.cursor() query = f""" SELECT target_sentences.sentence_id, target_sentences.text, "[sound:tatoeba_" || "{args.target}" || "_" || target_sentences.sentence_id || ".mp3]", "<ul class=""tags""><li>" || ( SELECT group_concat(tag_name, "</li><li>") FROM tags WHERE tags.sentence_id = target_sentences.sentence_id ) || "</li></ul>", {native_lang_columns()} FROM sentences AS target_sentences WHERE target_sentences.lang = "{args.target}" AND target_sentences.sentence_id IN (SELECT sentence_id FROM sentences_with_audio) ; """ if not os.path.exists('output'): os.makedirs('output') with open(f'{os.path.join(output_dir, args.target)} → {args.native}.csv', 'w', newline='') as csvfile: out = csv.writer(csvfile, delimiter='\t', quotechar='|', quoting=csv.QUOTE_MINIMAL) for row in c.execute(query): out.writerow(row) conn.close() if __name__ == '__main__': main() |
In order to produce, for example, a deck of Finnish sentences with audio along with translations into English, Russian, Spanish, Italian and Japanese (whenever available), we use it like this (with ISO 639-3 codes):
1 | ./query.py -t fin -n "eng rus spa ita jpn" |
Running the script will produce a CSV file in the output subdirectory.
2.4. Downloading the audio files
Each audio file is available from this URL: https://audio.tatoeba.org/sentences/sentence_id. In order to make a list of all of the files to be downloaded we use this Python script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #!/usr/bin/env python3 import argparse import csv import sqlite3 def main(): parser = argparse.ArgumentParser( description="Make a list of URLs of audio files for a specific language from the Tatoeba Project") parser.add_argument("-t", "--target", type=str, help="target language", required=True) parser.add_argument("-d", "--database", type=str, help="database file", default = "tatoeba.sqlite3") args = parser.parse_args() conn = sqlite3.connect(args.database) c = conn.cursor() query = f""" SELECT sentence_id FROM sentences WHERE lang = '{args.target}' AND sentence_id IN (SELECT sentence_id FROM sentences_with_audio) """ for row in c.execute(query): print("https://audio.tatoeba.org/sentences/" + args.target + "/" + str(row[0]) + ".mp3") if __name__ == '__main__': main() |
This shell script downloads the files and renames them properly:
1 2 3 4 5 6 7 8 9 10 | #!/usr/bin/sh mkdir -p output/audio # Source: https://stackoverflow.com/a/11850469 ./audio_urls.py -t $1 -d $2 | xargs -n 1 -P 2 wget --directory-prefix=output/audio/ --continue for f in output/audio/*; do mv "$f" "$(echo $f | sed 's/^output\/audio\//output\/audio\/tatoeba_'$1'_/g')"; done |
2.5. Creating a proper note type
Now that we have the data exported to an importable CSV files we want to create a proper note type for it (Tools → Manage Note Types → Add). We need the following fields: sentence_id, target (e.g. fin), audio, tags, and a field for each of the languages we are familiar with. In addition, we need these fields for MorphMan: MorphMan_FocusMorph, MorphMan_Index, MorphMan_Unmatures, MorphMan_UnmatureMorphCount, MorphMan_Unknowns, MorphMan_UnknownMorphCount, MorphMan_UnknownFreq. Delete the default Front and Back fields and close the window.
Now, pressing the Cards button will open a window similar to this:
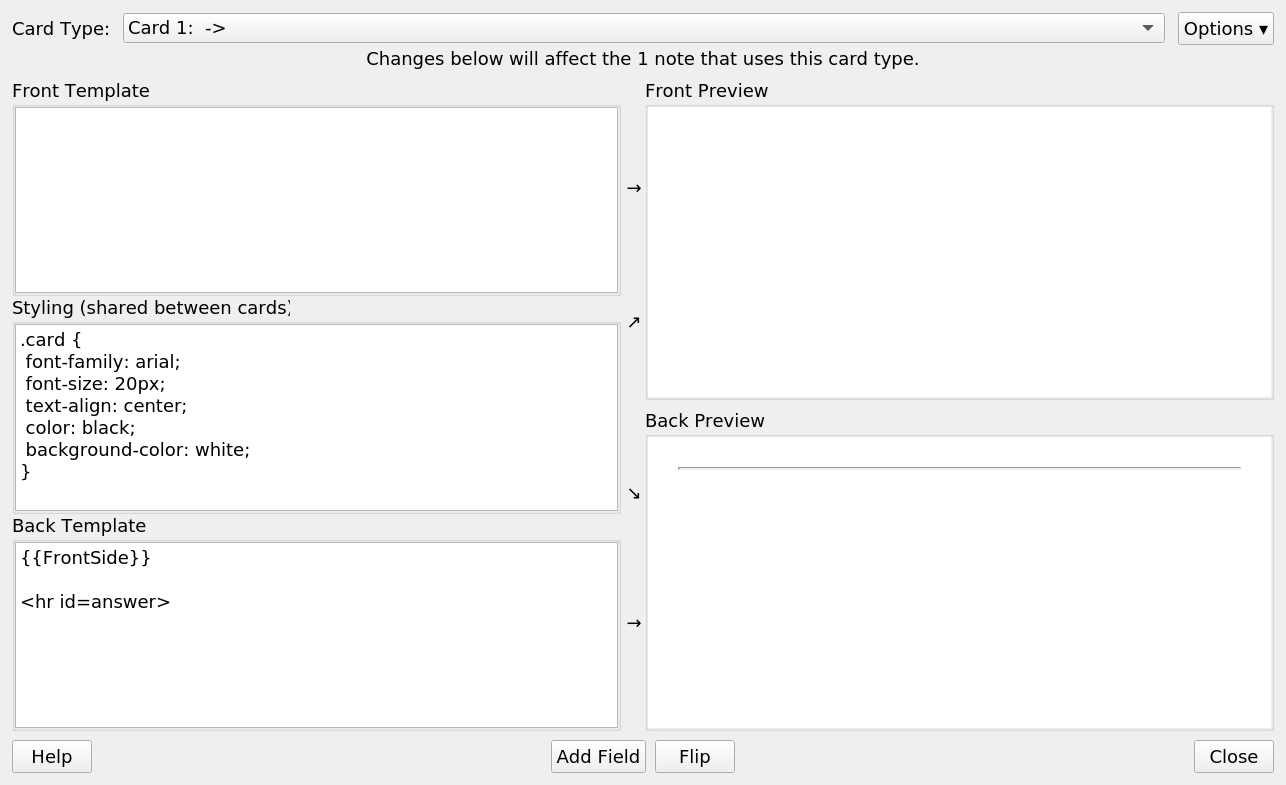
We create three cards: Reading, Listening and Production. For Reading in our Finnish exemple we write
1 | <p>fin</p> |
in the front template and
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | {{FrontSide}}
<hr id="answer">
<p id="tags">{{tags}}</p>
<p>{{eng}}</p>
<p>{{rus}}</p>
<p>{{spa}}</p>
<p>{{ita}}</p>
<p>{{jpn}}</p>
<p>{{audio}}</p>
<p id="tatoeba"><a href="https://tatoeba.org/eng/sentences/show/{{sentence_id}}"><img src="_tatoeba.svg" /></a></p>
|
in the back template.
The shared styling should be something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | .card { font-family: sans; font-size: 20px; text-align: center; color: #111; background-color: #fffff8; } .card.night_mode { background-color: #2E3440; color: #D8DEE9; } #lookup a, #tatoeba { color: inherit; text-decoration: inherit; } #tatoeba img { width: 1em; height: auto; } #tags { font-size: small; } .hebrew, .arabic { direction: rtl; } .translations, .tags { list-style-type: none; margin: 0; padding: 0; } .translations li, .tags li { display: inline; } .translations li:after, .tags li:after { content: " · " } .translations li:last-child:after, .tags li:last-child:after { content: "" } |
Listening’s front template:
1 | <p>{{audio}}</p> |
Listening’s back template:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | {{FrontSide}}
<hr id="answer">
<p id="lookup">{{fin}}</p>
<p id="tags">{{tags}}</p>
<p>{{eng}}</p>
<p>{{rus}}</p>
<p>{{spa}}</p>
<p>{{ita}}</p>
<p>{{jpn}}</p>
<p id="tatoeba"><a href="https://tatoeba.org/eng/sentences/show/{{sentence_id}}"><img src="_tatoeba.svg" /></a></p>
|
Production’s front template:
1 2 3 4 5 | <p>{{eng}}</p> <p>{{rus}}</p> <p>{{spa}}</p> <p>{{ita}}</p> <p>{{jpn}}</p> |
Production’s back template:
1 2 3 4 5 6 7 8 9 10 11 | {{FrontSide}}
<hr id="answer">
<p id="lookup">{{fin}}</p>
<p id="tags">{{tags}}</p>
<p>{{audio}}</p>
<p id="tatoeba"><a href="https://tatoeba.org/eng/sentences/show/{{sentence_id}}"><img src="_tatoeba.svg" /></a></p>
|
2.6. Importing into Anki
Import the CSV file (File → Import). Check Allow HTML in fields. The fields in the CSV file and our note type should match.
Copy the MP3 files to your media collection directory. Its location depends on your operating system; read more here. Download Tatoeba’s logo to the same directory, renaming it _tatoeba.svg.
{kind=link}
Now we have a working deck and it’s time to check it using the preview option of the Browse window.
2.7. Sorting the cards
One last thing you might want to do is to sort the cards so new words occur incrementally. MorphMan is an Anki addon that does just this. Read about it in the wiki and/or watch YouTube videos about it.
That’s it. Enjoy learning whatever language you want to learn :-)
If you benefit from Tatoeba please consider joining the project and contribute sentences, translations and audio recordings (see this guide), or donating money.
3. Precompiled decks
I made decks for all of the language in Tatoeba that have audio recordings (except English and Spanish, which have too many sentences) so people will not have to go through the pain (and pleasure…) of making them.
In order to obtain a list of the relevant languages we can run this query:
1 2 3 4 5 6 7 | .open tatoeba.sqlite3 SELECT lang, COUNT (sentences.sentence_id) AS audio_sentences_no FROM sentences_with_audio JOIN sentences ON sentences_with_audio.sentence_id = sentences.sentence_id GROUP BY lang ORDER BY audio_sentences_no DESC; |
I chose to include translation for the five languages that share most co-translated sentences with the target language. In order to check what these languages are we can run this query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | .open tatoeba.sqlite3 SELECT lang, COUNT (sentences.sentence_id) AS counter FROM sentences JOIN links ON sentences.sentence_id = links.translation_id WHERE links.sentence_id IN ( SELECT sentence_id FROM sentences WHERE lang = 'fin' AND sentence_id in (SELECT sentence_id FROM sentences_with_audio) ) GROUP BY lang ORDER BY counter DESC LIMIT 5; |
3.1. Downloading the decks
The result of the whole process was uploaded to AnkiWeb. The decks have names following this format, conforming to the 60 character limit:
1 | All LANGUAGE sentences with recorded audio from Tatoeba |
If you find the decks useful, please leave positive feedback on AnkiWeb: it will make me happy and will others find the decks.
For backup purposes you can download the decks from this website’s server; the link is designated by ⭳. I prefer you download the decks from AnkiWeb ( ), as decks that don’t get enough downloads are removed from AnkiWeb.
), as decks that don’t get enough downloads are removed from AnkiWeb.
A temporary note: one can share only 10 decks a week on AnkiWeb. This is the reason not all decks have AnkiWeb links. I hope soon I will be able to complete sharing all decks there.
| 19582 | German 1/2 | → | English (18733) | Esperanto (9873) | French (8322) | Russian (7717) | Spanish (6917) | 2019/10/12 | | ⭳ |
| German 2/2 | | ⭳ | ||||||||
| 11019 | Portuguese | → | English (10163) | Spanish (2282) | Esperanto (1704) | French (1080) | Russian (653) | 2019/10/12 | | ⭳ |
| 8181 | French | → | English (7956) | Esperanto (6280) | Russian (5051) | German (2921) | Ukrainian (2204) | 2019/10/12 | | ⭳ |
| 6720 | Hungarian | → | English (6048) | German (1263) | Esperanto (643) | Italian (529) | French (350) | 2019/10/12 | | ⭳ |
| 4690 | Russian | → | English (3294) | Japanese (1874) | French (1662) | German (1268) | Ukrainian (1246) | 2019/10/12 | | ⭳ |
| 4598 | Berber | → | English (4494) | Spanish (320) | French (315) | Kabyle (60) | Arabic (46) | 2019/10/12 | | ⭳ |
| 4601 | Esperanto | → | English (3901) | French (1340) | German (1172) | Dutch (748) | Spanish (570) | 2019/10/12 | | ⭳ |
| 4057 | Finnish | → | English (4017) | Russian (1174) | Spanish (1087) | Italian (766) | Japanese (286) | 2019/10/12 | | ⭳ |
| 2491 | Wu Chinese | → | Mandarin (2489) | French (633) | English (427) | Spanish (34) | Yue Chinese (32) | 2019/10/12 | | ⭳ |
| 1961 | Dutch | → | Esperanto (1935) | English (1698) | Ukrainian (1460) | German (1321) | Spanish (1231) | 2019/10/12 | | ⭳ |
| 1678 | Mandarin Chinese | → | French (1317) | German (1280) | English (1260) | Wu Chinese (700) | Spanish (605) | 2019/10/12 | | ⭳ |
| 1283 | Japanese | → | English (1278) | Russian (1249) | Finnish (1050) | German (1025) | French (658) | 2019/10/12 | | ⭳ |
| 1086 | Hebrew | → | English (1086) | Esperanto (125) | Polish (120) | Russian (89) | French (83) | 2019/10/12 | | ⭳ |
| 1067 | Latin | → | English (974) | Portugeuse (430) | Spanish (375) | French (293) | Esperanto (199) | 2019/10/12 | | ⭳ |
| 480 | Central Dusun | → | English (401) | Japanese (45) | Coastal Kadazan (31) | 2019/10/12 | | ⭳ | ||
| 376 | Marathi | → | English (376) | Hindi (142) | 2019/10/12 | | ⭳ | |||
| 363 | Ukrainian | → | English (363) | French (28) | German (20) | Italian (17) | Spanish (15) | 2019/10/12 | | ⭳ |
| 224 | Polish | → | English (222) | Dutch (98) | German (30) | Ukrainian (27) | Russian (21) | 2019/10/12 | | ⭳ |
| 134 | Thai | → | English (87) | Esperanto (39) | German (38) | French (38) | Russian (32) | 2019/10/12 | | ⭳ |
| 112 | Catalan | → | English (111) | Spanish (41) | Ukrainian (31) | French (19) | Esperanto (17) | 2019/10/12 | ⭳ | |
| 60 | Chavacano | → | English (53) | 2019/10/12 | ⭳ | |||||
| 53 | Romanian | → | English (51) | Esperanto (51) | Dutch (50) | German (34) | Spanish (34) | 2019/10/12 | ⭳ | |
| 37 | Turkish | → | English (37) | German (13) | Esperanto (8) | Spanish (5) | Swedish (3) | 2019/10/12 | ⭳ | |
| 28 | Naga (Tangshang) | → | English (28) | 2019/10/12 | ⭳ |