הפקת חפיסות עם שמע מפרוייקט טטואבה
אם אתן מחפשות להוריד חפיסות מוכנות של משפטים עם הקלטות אודיו, כאן יש רשימה.
An English version of this page is available here.
1. רקע
 בדף הזה אתאר שיטה ליצירה אוטומטית של חפיסות מהסוג שלדעתי הוא הכי אפקטיבי: הלימוד בעזרתן הוא המהיר ביותר, הקל ביותר ומקנה את ההבנה השלמה ביותר. העקרון פשוט, ובנוי מכמה חלקים:
בדף הזה אתאר שיטה ליצירה אוטומטית של חפיסות מהסוג שלדעתי הוא הכי אפקטיבי: הלימוד בעזרתן הוא המהיר ביותר, הקל ביותר ומקנה את ההבנה השלמה ביותר. העקרון פשוט, ובנוי מכמה חלקים:
- בכל שלב בלימוד נקרא לסך הידע על השפה i: כל מה שאתן יודעות עד אותה הנקודה. העקרון הוא שכשלומדות דבר חדש, תמיד טוב לבנות על הקיים ולהוסיף באופן הדרגתי: לא לקפוץ מהר מדי גבוה מדי וגם לא להתפרש לרוחב בלי לנצל את העוגנים שאפשר להעזר בהם בידע הקיים. במילים אחרות, אנחנו רוצות ללמוד בכל שלב i+1, כלומר להוסיף משהו חדש אחד על הידע הקיים ולהתבסס עליו.
- הנדבך השני הוא לימוד של משפטים, ולא של מילים מנותקות מהקשר. אנחנו רגילות מבית־הספר ללמוד מילים בנפרד; זאת דרך קשה ולא אפקטיבית ללימוד אוצר מילים. נחשוב, לדוגמה, על מקרה כמו של get באנגלית: יש לה 31 פירושים בוויקימילון, ולימוד שלהם באופן ערטילאי נדון לכשלון. לעומת זאת, אם אנחנו לומדות משפטים קצרים וממוקדים, גם קל יותר לזכור את המילים החדשות וגם אפשר להבין אותן ואת אופני השימוש האידיומטיים בהן באופן טוב יותר. הופעה של אותה המילה במשפטים שונים תאיר פנים שונות שלה ושל השימוש הטבעי בה, גם מבחינת מבנים לשוניים וגם מבחינת דקויות משמעות. המשפטים צריכים להיות קצרים מספיק כדי שיהיה קל לזכור אותם באופן לא מעורפל, והם צריכים גם להיות עצמאיים מבחינה פרגמטית (כלומר, שאפשר להבין אותם במנותק מהקשר רחב יותר בשיחה).
- החלק השלישי בעקרון המנחה הוא ששפה, עבור רובנו, נטועה לא רק בחוש הראיה — שפה כתובה — אלא גם ובעיקר בחוש השמיעה. ללמוד שפה בלי לשמוע אותה ובלי לגלגל אותה על הלשון זה סוג של „People talking without speaking” מ־The Sound of Silence.גם בשפות מתות יש, לדעתי, ערך בשמיעה ובתרגול של אופן ההיגוי המשוחזר. הכי טוב זה לעשות שימוש פעיל בשפה ביחד עם דוברות ילידיות, בין אם בחילופי־שפות ובין אם במפגש מסוג אחר (מתווך־מחשב או לא), אבל לא תמיד אנחנו לומדות שפות שיש לנו דרך לדבר בהן עם דוברות ילידיות ולא תמיד זה מתאים לנו או להן. כעזר מלאכותי אפשר להשתמש בהקלטות של דוברות ילידיות של המשפטים שדיברנו עליהם קודם. זה מאפשר לנו גם לדעת איך להגות נכון ובמקצב ובאינטונציה טבעייםבהקשר הזה כדאי להכיר טכניקה מועילה מאוד בשם shadowing. אפשר ללמוד עליה גם מסרטונים ביוטיוב. עד כמה שניתן וגם להתאמן על הבנת הנשמע (כשבחלק הקדמי של הכרטיס יש את השמע ובחלק האחורי את המשפט הכתוב בשפה הנלמדת ואת פשרו בשפה/ות שאנחנו יודעות). יש מי שמשתמשות בשמע מסונתז; אמנם התחום הזה ראה שיפור כביר בשנים האחרונות, אבל אני עדיין ממליץ לכן להשתמש בשמע מסונתז רק אם אתן רוצות להשמע כמו רובוט…
אם נסכם את שלושת החלקים נקבל: לימוד של משפטים קצרים ועצמאיים־פרגמטית עם שמע טבעי שמסודרים באופן הדרגתי. נכון הגיוני?
עכשיו עולה השאלה מאיפה אנחנו משיגות משפטים כאלה (רצוי עם תרגום לשפה שאנחנו כבר מכירות היטב), ולא רק זה אלא גם שמע מוקלט שלהם, ולא רק זה אלא גם שהם יהיו מסודרים בסדר הטוב ביותר, שמציג לנו בכל פעם כמה שפחות מידע חדש ובונה על הקיים. כאן בדיוק נכנס הדף הזה: את המשפטים נוריד באופן אוטומטי מפרוייקט מופלא בשם Tatoeba ואת הסידור נעשה בעזרת תוסף לאנקי בשם MorphMan. כדי לחסוך לכן את העבודה שבלעשות את התהליך מחדש, יצרתי חפיסות מוכנות עבור כל השפות שיש להן משפטים מוקלטים בטטואבה.
פרוייקט טטואבה הוא מיזם שיתופי־ציבורי ליצירה של מאגר רב־לשוני של משפטים לדוגמה שמתורגמים בין שפותגם באופן ישיר (לדוגמה, משפט ביפנית שמתורגם ישירות לעברית על ידי דוברת עברית שיודעת יפנית) וגם באופן עקיף (לדוגמה, אם התרגום העברי של המשפט היפני תורגם למאורית על ידי דוברת מאורית שיודעת עברית, יש גם קשר עקיף בין המשפט היפני והמאורי, למרות שהוא בתיווך עברי).. לחלק מהמשפטים יש גם הקלטות באתר; נכון לזמן כתיבת שורות אלה יש 7,853,301 משפטים בסך הכל, מתוכם 637,768 גם מוקלטים. לא רק שזה מיזם שיתופי וציבורי, הוא גם פתוח וחופשי: כל הטקסט וחלק מהשמע משוחרר תחת רשיונות חופשיים ואפשר להוריד את קבצי מסד הנתונים באופן נוח.
לא כל המשפטים באותה הרמה. כמו בכל מיזם שיתופי כזה, תמיד יהיו טעויות ורשומות באיכות נמוכה יותרהבעיה היא גם בטעויות של דוברים ילידיים (קורה!), אבל בעיקר במי שלומדות שפה כלשהי ובוחרות להתאמן בה בטטואבה, למרות הבקשות המפורשות באתר להמנע מכך. אם אתן רוצות להתאמן בכתיבה ולקבל משוב מדוברות ילידיות, Lang-8 הוא האתר בשבילכן.; כמו ברוב המיזמים האלה, המתנדבות תמיד פועלות כדי לשפר את האיכות ולנפות החוצה רשומות לא מתאימות. לצרכינו עצם קיומה של הקלטה למשפט כבר עושה סינון טוב: אם דוברת של השפה בחרה לטרוח ולהקליט אותו, כנראה שהוא נכון וטבעי. למרות זאת כדאי להיות זהירות, במיוחד בתרגומים של המשפטים לשפות אחרות.
2. תהליך ההפקה
בסעיף הזה אתאר איך ליצור חפיסות בעצמכן מהנתונים שבטטואבה. התהליך דורש ידע טכני במחשבים שאין לכולן. את המערכת בניתי בגנו/לינוקס, אבל אין סיבה עקרונית שזה לא יעבוד גם ב־macOS או ב„חלונות” בעזרת Cygwin או מערכת דומה. הכלים שבהם נעשה שימוש הם: sh, Wget, tar, bzip2, sed, uniq, SQLite, ו־Python. זאת דוגמה יפה, לדעתי, לאופי המודולרי של הכלים האלה: כל אחד מצידו עושה משהו אחד, עושה אותו טוב, ומאפשר שיתוף פעולה עם כלים אחרים, כמו חלקים של לגו שמתחברים אחד לשני.
אם זה מעניין אתכן ועדיין אין לכן את הידע תוכלו להשתמש בזה כשער לעבור דרכו וללמוד, אבל ברור לי שלא לכולן זה מתאים. אם מסיבה כלשהי החפיסות המוכנות לא עונות על צרכיך ויש לך צורך בעזרה, כתבי לי ואנסה לעזור במה שצריך, בין אם בהנחיה או בבניה של חפיסה ושליחה שלה. אחרי שכבר בניתי את המערכת ואני מכיר אותה זה לוקח לי רגע להכין חפיסות.
2.1. הורדה של הנתונים
השלב הראשון הוא להוריד את קבצי מסד הנתונים של טטואבה. הם מיוצאים באופן אוטומטי כקבצי CSV. הקבצים שאנחנו צריכות הם:
sentences.csv: כל המשפטים (הצמתים בגרף).links.csv: הקשרים בין המשפטים (הקשתות בגרף, לא מכוונות ומופיעות פעמים, כ־A→B וכ־B→A): איזה משפט מקביל לאיזה משפט.tags.csv: משפטים יכולים להיות מסומנים בתגים (לדוגמה,colloquialבשביל לסמן משלב דיבורי).sentences_with_audio.csv: רשימה של המשפטים שיש להם קבצי שמע, עם מטא־נתונים על המקליטות והרשיונות.
אנחנו רוצות להוריד אותם, לפרוס את הדחיסה, ולעשות באופן אוטומטי כמה תיקונים כדי שנוכל להשתמש בהם בהמשך, כך:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | #!/usr/bin/sh mkdir -p csv pushd csv # Download wget https://downloads.tatoeba.org/exports/sentences.tar.bz2 wget https://downloads.tatoeba.org/exports/links.tar.bz2 wget https://downloads.tatoeba.org/exports/tags.tar.bz2 wget https://downloads.tatoeba.org/exports/sentences_with_audio.tar.bz2 # Decompress and untar for f in *.tar.bz2; do tar jxf $f done # Prepare sed 's/"/""/g;s/[^\t]*/"&"/g' sentences.csv > sentences.escaped_quotes.csv sed 's/"/""/g;s/[^\t]*/"&"/g' tags.csv > tags.escaped_quotes.csv uniq sentences_with_audio.csv > sentences_with_audio.uniq.csv # Remove compressed files rm -i {sentences, links, tags, sentences_with_audio}.tar.bz popd |
כדי להריץ זה נפקוד sh download_and_prepare_csv.sh בספריה אליה הורדנו הקובץ ה־sh.
2.2. יצירת מסד נתונים מקומי
עכשיו נוכל לייבא את הנתונים מקבצי ה־CSV למסד נתונים, אליו נוכל לשלוח שאילתות SQL. נשתמש ב־SQLite בגלל שהוא מקומי, מהיר, נוח ולא דורש התעסקות. קובץ ה־SQL הזה יוצר קובץ מסד נתונים, מוסיף לו טבלאות ומייבא אליו את הנתונים:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | .open tatoeba.sqlite3 -- Tatoeba’s database has many deleted entries in `sentences` which are referenced from `sentences_with_audio` and `links`; expect tons of warning messages PRAGMA foreign_keys = ON; CREATE TABLE sentences ( sentence_id INTEGER PRIMARY KEY, lang TEXT, text TEXT ); CREATE TABLE sentences_with_audio ( sentence_id INTEGER PRIMARY KEY, username TEXT, license TEXT, attribution_url TEXT, FOREIGN KEY (sentence_id) REFERENCES sentences(sentence_id) ); CREATE TABLE links ( sentence_id INTEGER, translation_id INTEGER, FOREIGN KEY (sentence_id) REFERENCES sentences(sentence_id), FOREIGN KEY (translation_id) REFERENCES sentences(sentence_id) ); CREATE TABLE tags ( sentence_id INTEGER, tag_name TEXT, FOREIGN KEY (sentence_id) REFERENCES sentences(sentence_id) ); CREATE INDEX links_index ON links(sentence_id, translation_id); CREATE INDEX tags_index ON tags(sentence_id, tag_name); .separator "\t" .import csv/sentences.escaped_quotes.csv sentences .import csv/sentences_with_audio.uniq.csv sentences_with_audio .import csv/links.csv links .import csv/tags.escaped_quotes.csv tags |
כדי להריץ אותו נפקוד sqlite3 -init create_db.sql. צפו להמון אזהרות; מסד הנתונים של טטואבה כולל המון הפניות למשפטים שנמחקו כבר.
2.3. יצירת שאילתה מתאימה על הנתונים
עכשיו כשיש לנו מסד נתונים עם כל המידע הדרוש נוכל להשתמש בו כדי לקבל את המידע שאנחנו רוצות. רגע, מה המידע שאנחנו רוצות? קובץ שבכל שורה שלו יש את הנתונים הבאים:
- מספר המשפט במערכת של טטואבה. בעזרת המספר הזה אפשר לקשר מתוך הכרטיס באנקי אל העמוד המתאים בטטואבה באופן אוטומטי.
- הטקסט של המשפט בשפה שאנחנו לומדות.
- הפניה לקובץ של ההקלטה.
- התגים של המשפט.
- תרגומים של המשפט לשפות שאנחנו מכירות. בכוונה בחרתי שלא לכלול תרגום עקיף (כמו בדוגמה של יפנית ← עברית ← מאורית למעלה), גם כי זה מעט מורכב יותר למימוש ובעיקר בגלל שמשפטים בדרגת קרבה רחוקה יותר יכולים להיות שונים תחבירית ולקסיקלית באופן מטעה, כמו סוג של טלפון שבור.
לצורך זה כתבתי את הסקריפט הזה בפייתון. אולי הוא לא הכי קצר ואלגנטי שאפשראם יש לכן הצעות לשיפור ופִייתוּן, אשמח לשמוע., אבל הוא עובד טוב.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | #!/usr/bin/env python3 import argparse import csv import os import sqlite3 output_dir = 'output' native_langs = [] def native_lang_columns(): def native_lang_column(lang): return f""" "<ul class=""translations""><li>" || ( SELECT group_concat(sentences.text, "</li><li>") FROM links JOIN sentences ON links.translation_id = sentences.sentence_id WHERE links.sentence_id = target_sentences.sentence_id AND sentences.lang = '{lang}' ) || "</li></ul>" """ result = "" for lang in native_langs[:-1]: result += native_lang_column(lang) + ", " result += native_lang_column(native_langs[-1]) return result def main(): parser = argparse.ArgumentParser( description="Make a CSV files of sentences from the Tatoeba Project that have audio, along with their translations into selected languages") parser.add_argument("-t", "--target", type=str, help="target language", required=True) parser.add_argument("-n", "--native", type=str, help="native languages (space-delimited, within quotes)", required=True) parser.add_argument("-d", "--database", type=str, help="database file", default = "tatoeba.sqlite3") args = parser.parse_args() global native_langs native_langs = args.native.split(" ") conn = sqlite3.connect(args.database) c = conn.cursor() query = f""" SELECT target_sentences.sentence_id, target_sentences.text, "[sound:tatoeba_" || "{args.target}" || "_" || target_sentences.sentence_id || ".mp3]", "<ul class=""tags""><li>" || ( SELECT group_concat(tag_name, "</li><li>") FROM tags WHERE tags.sentence_id = target_sentences.sentence_id ) || "</li></ul>", {native_lang_columns()} FROM sentences AS target_sentences WHERE target_sentences.lang = "{args.target}" AND target_sentences.sentence_id IN (SELECT sentence_id FROM sentences_with_audio) ; """ if not os.path.exists('output'): os.makedirs('output') with open(f'{os.path.join(output_dir, args.target)} → {args.native}.csv', 'w', newline='') as csvfile: out = csv.writer(csvfile, delimiter='\t', quotechar='|', quoting=csv.QUOTE_MINIMAL) for row in c.execute(query): out.writerow(row) conn.close() if __name__ == '__main__': main() |
השימוש בסקריפט פשוט: python query.py -t target -n native, כש־target הוא קוד ISO 639-3 שמצייג השפה שאנחנו רוצות ללמוד ו־native רשימה של השפות שאנחנו יודעות (תחומות במירכאות ישרות ומופרדות ברווח). כך, לדוגמה, יצרתי לי את החפיסה שאני משתמש בה ללימוד פינית, עם תרגומים לשפות בהן אני שולט באופן החופשי ביותר (אנגלית, עברית, וולשית, נורווגית ואספרנטו):
1 | python query.py -t fin -n "eng heb cym nob epo" |
אחרי שהסקריפט ירוץ נקבל בתוך תת־הספריה output קובץ CSV עם המשפטים שלנו. אפשר כבר להתחיל לראות את הסוף…
2.4. הורדת קבצי הקול
לפני שנרוץ לייבא את הנתונים האלה לאנקי, נרצה להוריד את קבצי הקול. אין מאגר אחד להורדה, כך שנצטרך להוריד קובץ־קובץ. למזלנו, יש לנו כלים אוטומטיים שיכולים לעשות את זה בשבילנו.
כתבתי את הסקריפט הבא, שמייצר רשימה של קבצי הקול, כל קובץ בשורה נפרדת:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #!/usr/bin/env python3 import argparse import csv import sqlite3 def main(): parser = argparse.ArgumentParser( description="Make a list of URLs of audio files for a specific language from the Tatoeba Project") parser.add_argument("-t", "--target", type=str, help="target language", required=True) parser.add_argument("-d", "--database", type=str, help="database file", default = "tatoeba.sqlite3") args = parser.parse_args() conn = sqlite3.connect(args.database) c = conn.cursor() query = f""" SELECT sentence_id FROM sentences WHERE lang = '{args.target}' AND sentence_id IN (SELECT sentence_id FROM sentences_with_audio) """ for row in c.execute(query): print("https://audio.tatoeba.org/sentences/" + args.target + "/" + str(row[0]) + ".mp3") if __name__ == '__main__': main() |
נרצה לא רק להוריד את הקבצים בצורה מסודרת, אוטומטית ומהירה, אלא גם לתת להם קידומת tatoeba_target_ כדי שלא יהיה בלגאן באוסף קבצי המדיה של אנקי. כדי לעשות את זה נשתמש בסקריפט:
1 2 3 4 5 6 7 8 9 10 | #!/usr/bin/sh mkdir -p output/audio # Source: https://stackoverflow.com/a/11850469 ./audio_urls.py -t $1 -d $2 | xargs -n 1 -P 2 wget --directory-prefix=output/audio/ --continue for f in output/audio/*; do mv "$f" "$(echo $f | sed 's/^output\/audio\//output\/audio\/tatoeba_'$1'_/g')"; done |
ההורדה היא של שני קבצים במקביל, כך שבזמן שמחכים לבקשה של קובץ אחד השני ממשיך לרדת ולא מחכים בצוואר בקבוק. למה רק שניים? כי התפוקה פוחתת ככל שמוסיפים עוד הורדות במקביל, כי חבל סתם להעמיס על השרתים של טטואבה וכי הורדה של יותר מדי קבצים במקביל יכולה להסתיים בזה שההורדה של חלקם תשתבש (מנסיון…).
2.5. יצירת סוג רשומה מתאים
עכשיו נרצה שתהיה לנו תבנית של רשומות כדי שנוכל לייבא את הקבצים אל אנקי. כדי ליצור תבנית כזאת נבחר Tools → Manage Note Types מהתפריט ושם נלחץ על Add, נוסיף תבנית בסיסית ונקרא לה בשם. נחפש אותה ברשימת התבניות ונלחץ על Fields. נוסיף את השדות שאנחנו צריכות (אפשר לבחור גם שמות אחרים, כמובן, וסדר אחר):
sentence_id, בשביל מספר המשפט במאגר של טטואבה.- שדה בשביל השפה שאנחנו לומדות. לי נוח פשוט לקרוא לשדה בשם מ־ISO 639-3.
audio, שיפנה לקובץ השמע.tags, בשביל התגים מטטואבה. יש לאנקי שדה פנימי של תגים, שמאפשר לחפש לפיהם. השדה כאן מיועד להצגה על גבי הכרטיסים.- שדה עבור כל אחת מהשפות שאנחנו יודעות כבר.
- אם אתן רוצות להשאיר את השדות עם המשפטים בלי שינוי ולכתוב הערות שלכן בשדות נפרדים, אפשר ליצור שדות שמיועדים להערות.
- שדות בשביל התוסף MorphMan שמסדר את הכרטיסים בסדר i+1, כדי שהוא יוכל לשמור נתונים על כל רשומה:
MorphMan_FocusMorph,MorphMan_Index,MorphMan_Unmatures,MorphMan_UnmatureMorphCount,MorphMan_Unknowns,MorphMan_UnknownMorphCount,MorphMan_UnknownFreq. על השמות האלה נשמור כמות שהם.
אחרי שהוספנו את השדות החדשים נוכל למחוק את ה־Front וה־Back שמגיעים ביחד עם התבנית הבסיסית ולסגור את החלון של השדות.
נלחץ על Cards ויפתח לנו חלון כזה:
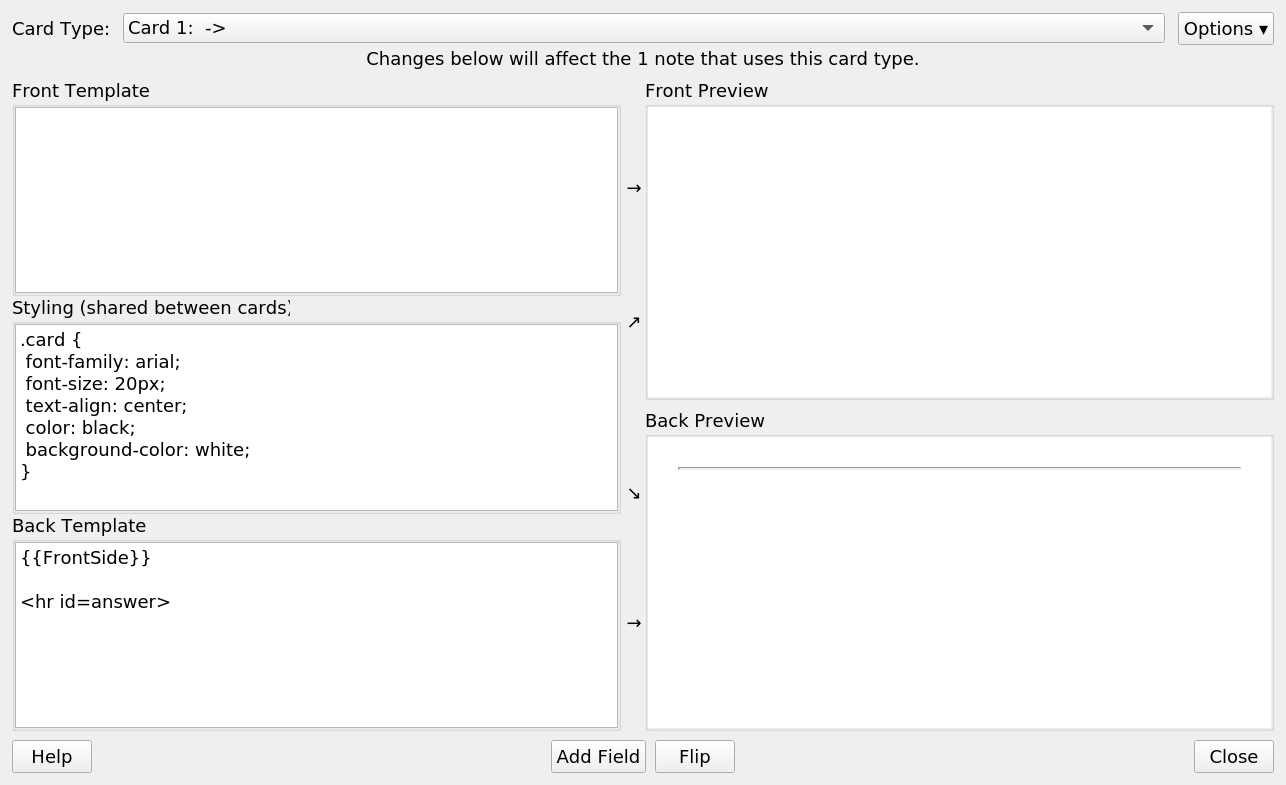
בראש החלון נוכל לבחור בין סוגי הכרטיסים שנרצה ליצור מכל רשומה. אני ממליץ על שלושה כיוונים לפי הסדר הזה:
- הבנת הנקרא, כלומר: בצד הקדמי (השאלה) יופיע המשפט הכתוב שאנחנו לומדות ובאחורי (התשובה) השמע והתרגומים.
- הבנת הנשמע, כלומר: בצד הקדמי תושמע ההקלטה ובאחורי המלל הכתוב והתרגומים.
- הפקה אקטיבית, כלומר: בצד הקדמי יופיעו התרגומים ובאחורי המשפט בשפה שאנחנו לומדות, כתוב ומושמע.
הסדר הזה הוא, מנסיוני, הסדר הכי טוב ללמוד בו.
נתחיל בסידור הכיוון הראשון. בצד שמאל למעלה (Front Template) נכתוב
1 | <p>{{TARGET}}</p> |
כשאת target נחליף בשם של השדה של הטקסט בשפה הנלמדת. אם תרצו לחפש מילים במילון בלחיצת כפתור קראו את הדף הזה וכתבו במקום השורה הזו את זו:
1 | <p id="lookup">{{TARGET}}</p> |
למטה (Back Template) נוסיף את השדה של התגים, של השמע ואת השדות של השפות שאנחנו יודעות, כך לדוגמה:
1 2 3 4 5 6 7 8 9 10 11 | <p id="tags">{{tags}}</p> <p class="hebrew">{{heb}}</p> <p>{{eng}}</p> <p>{{nob}}</p> <p>{{cym}}</p> <p>{{epo}}</p> <p>{{audio}}</p> <p id="tatoeba"><a href="https://tatoeba.org/eng/sentences/show/{{sentence_id}}"><img src="_tatoeba.svg" /></a></p> |
השורה האחרונה מקשרת לדף של המשפט בטטואבה.
התגים והעברית מוגדרים בעיצוב מיוחד: את התגים נרצה להציג פחות בולטים ואת העברית בכיוון ימין←שמאל ולא שמאל←ימין. נגדיר את העיצוב בחלק האמצעי (Styling) כך לדוגמה, ב־CSS:
1 2 3 4 5 6 7 | #tags { font-size: small; } .hebrew { direction: rtl; } |
בנוסף, אם נרצה שהתרגומים השונים לאותה השפה יופיעו בצורה יפה, אחד לצד השני, ולא אחד מתחת לשני ברשימה עם תבליטים (•), נוכל להוסיף את המוג׳ו הבא לחלון העיצוב:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | .translations { list-style-type: none; margin: 0; padding: 0; } .translations li { display: inline; } .translations li:after { content: " · " } .translations li:last-child:after { content: "" } |
עכשיו נעבור ליצירת סוג הכרטיסים הבא על ידי לחיצה על הכפתור Options שבפינה הימנית העליונה ובחירה ב־Add Card Type. בדומה, הפעם נציב בחלק הקדמי את השדה של השמע ובאחורי את המלל הכתוב, התגים והשפות האחרות. לבסוף ניצור את הכיוון של ההפקה האקטיבית.
2.6. ייבוא אל אנקי
עכשיו אנחנו בשלות לשלב הכמעט־אחרון: אחרי שיש לנו גם קובץ CSV מוכן ותבנית עבורו וגם קבצי שמע שהורדנו נוכל לייבא אותם אל אנקי.
נתחיל בקובץ ה־CSV. מהחלון הראשי של אנקי נבחר File → Import וניגש את המקום שבו שמרנו את הקובץ. נבחר בסוג הרשומות שיצרנו, ובחפיסה המתאימה (נוכל להוסיף אחת אם אין כזו עדיין). חשוב ש־Allow HTML in fields. עכשיו נמפה את השדות בקובץ לשדות המתאימים בסוג הרשומות שלנו. הראשון הוא מספר המשפט, השני הטקסט בשפה הנלמדת, השלישי השמע, הרביעי התגים, והחמישי ואילך הם של השפות שנרצה לראות את התרגומים בהן, לפי אותו סדר שהזנו לסקריפט לפני עידן ועידנים. נייבא בעזרת לחיצה על Import.
עכשיו נעתיק את כל קבצי ה־MP3 לספריית המדיה של אנקי. המיקום שלה תלוי במערכת ההפעלה בה אתן משתמשות. פירוט עבור לינוקס, מקינטוש וחלונות נמצא בסעיף המתאים במדריך.
נוריד גם את הלוגו של טטואבה לאותה הספריה ונשנה את שם הקובץ ל־_tatoeba.svg.
{kind=link}
זהו. עכשיו אפשר לבדוק בעזרת האפשרות Browse ולראות שהכל עובד כראוי בלחיצה על Preview. הסדר של הכרטיסים הוא זה שהופיע במסד הנתונים, ועכשיו נרצה לשנות אותו.
2.7. סידור הכרטיסים
כדי לעשות את זה נעזר בתוסף לאנקי בשם MorphMan. אני לא רואה טעם לכתוב כאן מדריך עבור MorphMan; יש הסברים ברורים בוויקי ובסרטונים ביוטיוב.
בגדול מה שתצטרכו לעשות הוא:
- להתקין את התוסף בעזרת Tools → Add-ons, לחיצה על Get Add-ons והקלדת המספר של התוסף — 900801631 — בחלון שיפתח. כדי להשתמש בתוסף תצטרכו לסגור ולפתוח מחדש את אנקי.
- להוסיף ולהפעיל את סוג הכרטיסים שלנו במסך ההגדרות של התוסף (Tools → MorphMan Preferences) ואז להורות על חישוב מחדש של סדר הכרטיסים (Tools → MorphMan Recalc).
זהו זה! עכשיו הכל מוכן והגיע הזמן להתחיל ללמוד בשצף, פינית, לטינית, ברברית, יפנית או מה שבא לכן!
אתן מפיקות תועלת מטטואבה? שווה לשקול לעזור לפרוייקט החמוד והמעולה הזה: דרך אחת היא להצטרף ולתרום משפטים, תרגומים והקלטות (ר׳ מדריך); דרך אחרת היא לתרום תרומה כספית.
3. אחרית דבר: חפיסות מוכנות
התהליך שאני מתאר כאן אמנם עושה את העבודה בצורה טובה ואוטומטית, אבל דורש ידע ומצריך גם עבודה ידנית. זאת לא משימה שעושים באופן תכוף מספיק כדי להצדיק כתיבה של כלי אחת מהוקצה שיעשה את הכל באופן אוטומטי לגמרי, בלי טרחה ידנית.
כדי שכמה שיותר לומדות של שפות שונות — כולל שפות שאישית אני לא לומד — יוכלו להנות מהתוצרים של התהליך הפקתי חפיסות מוכנות עבור כל השפות שיש עבורן הקלטות במאגר.
3.1. רשימת השפות שיש להן הקלטות
בשלב ראשון נרצה לדעת לאיזה שפות יש בכלל הקלטות וכמה. אפשר להסתכל ולבדוק באתר כמו בני־תמותה פשוטים, אבל כשיש לנו SQL בידיים כל דבר נראה כמו שאילתה:
1 2 3 4 5 6 7 | .open tatoeba.sqlite3 SELECT lang, COUNT (sentences.sentence_id) AS audio_sentences_no FROM sentences_with_audio JOIN sentences ON sentences_with_audio.sentence_id = sentences.sentence_id GROUP BY lang ORDER BY audio_sentences_no DESC; |
מבט חטוף בתוצאה המתקבלת מגלה תמונה מעניינת ומאוד לא מאוזנת. טטואבה הוא מיזם שיתופי, מה שאומר שאם יש מי שיטרחו בשביל שפה מסויימת יהיו בה חומרים, ואם אין אז לא. בדיוק מהסיבה הזאת לשפות בֶּרְבֶּרְיוֹת יש יצוג עצום (במקום השלישי, אחרי אנגלית וספרדית, נמצאת Kabyle וכמה מקומות מתחתיה Berber), בעוד שאין הקלטה אפילו למשפט בודד באיטלקית למרות שזו השפה השניה מבחינת מספר המשפטים הכתובים…
מסקנה שניה היא שאין טעם לנסות להפיק חפיסות עבור אנגלית וספרדית, כי היו יוצאות חפיסות כבדות מדיכ־6 ג׳יגה ו־1 ג׳יגה בהתאמה, לפי ההערכה שלי שמתבססת על המשקל של משפט ממוצע בפינית. שדורשות זמן בלתי סביר כדי ללמוד אותן (במקרה של אנגלית, יותר מתקופת חיים אחת…), ובכל מקרה יש כבר די והותר חומרים ללימוד השפות האימפריאליסטיות האלה בנמצא.
3.2. בחירת השפות לתרגום
יש צמדים של שפת מקור ושפת תרגום שהם יותר נפוצים וכאלה שפחות. זה קשור לסיבות חברתיות־גיאוגרפיות־היסטוריות, אבל גם זה גם יכול להיות תוצאה של מישהי נמרצת מאוד שטרחה ותרגמה הרבה משפטים משפה אחת לאחרת. בפועל, לא משנה מה הסיבה, נרצה שהחלק של התרגומים בחפיסות יהיה כמה שיותר שלם. לכן, עבור כל שפה צירפתי תרגומים בחמשת השפות שיש הכי הרבה משפטים קוֹ־מתורגמים איתן. כדי לדעת מה הן כתבתי את השאילתה הזאת:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | .open tatoeba.sqlite3 SELECT lang, COUNT (sentences.sentence_id) AS counter FROM sentences JOIN links ON sentences.sentence_id = links.translation_id WHERE links.sentence_id IN ( SELECT sentence_id FROM sentences WHERE lang = TARGET AND sentence_id in (SELECT sentence_id FROM sentences_with_audio) ) GROUP BY lang ORDER BY counter DESC LIMIT 5; |
3.3. הורדת החפיסות
את התוצאה של כל התהליך העלתי למאגר החפיסות המוכנות של AnkiWebקישור לכלל החפיסות שהעלתי. בחרתי בפורמט אחיד לשם של החפיסות, במגבלת 60 התווים הנתונה:
1 | All LANGUAGE sentences with recorded audio from Tatoeba |
להלן רשימת החפיסות. אם החפיסות שימושיות עבורכן, בבקשה השאירו פידבק חיובי ב־AnkiWeb: זה גם יהיה נחמד עבורי, וגם יעזור לאחרות למצוא את החפיסות.
לצרכי גיבוי מופיעה גם אופציה להורדה מהשרת של „מילים דיגיטליות”, ומסומנת ב־⭳. אני מעדיף שתורידו מ־AnkiWeb (סימון:  ); חפיסות שלא זוכות למספיק הורדות מוסרות מהמאגר, ולא הייתי רוצה להכשיל את עצמי.
); חפיסות שלא זוכות למספיק הורדות מוסרות מהמאגר, ולא הייתי רוצה להכשיל את עצמי.
הערה זמנית: ניתן לשתף ב־AnkiWeb רק 10 חפיסות בשבוע. לכן לחלק מהחפיסות אין עדיין קישורים. בקרוב אוכל לסיים לשתף את הכל.
| 19582 | German 1/2 | → | English (18733) | Esperanto (9873) | French (8322) | Russian (7717) | Spanish (6917) | 2019/10/12 | | ⭳ |
| German 2/2 | | ⭳ | ||||||||
| 11019 | Portuguese | → | English (10163) | Spanish (2282) | Esperanto (1704) | French (1080) | Russian (653) | 2019/10/12 | | ⭳ |
| 8181 | French | → | English (7956) | Esperanto (6280) | Russian (5051) | German (2921) | Ukrainian (2204) | 2019/10/12 | | ⭳ |
| 6720 | Hungarian | → | English (6048) | German (1263) | Esperanto (643) | Italian (529) | French (350) | 2019/10/12 | | ⭳ |
| 4690 | Russian | → | English (3294) | Japanese (1874) | French (1662) | German (1268) | Ukrainian (1246) | 2019/10/12 | | ⭳ |
| 4598 | Berber | → | English (4494) | Spanish (320) | French (315) | Kabyle (60) | Arabic (46) | 2019/10/12 | | ⭳ |
| 4601 | Esperanto | → | English (3901) | French (1340) | German (1172) | Dutch (748) | Spanish (570) | 2019/10/12 | | ⭳ |
| 4057 | Finnish | → | English (4017) | Russian (1174) | Spanish (1087) | Italian (766) | Japanese (286) | 2019/10/12 | | ⭳ |
| 2491 | Wu Chinese | → | Mandarin (2489) | French (633) | English (427) | Spanish (34) | Yue Chinese (32) | 2019/10/12 | | ⭳ |
| 1961 | Dutch | → | Esperanto (1935) | English (1698) | Ukrainian (1460) | German (1321) | Spanish (1231) | 2019/10/12 | | ⭳ |
| 1678 | Mandarin Chinese | → | French (1317) | German (1280) | English (1260) | Wu Chinese (700) | Spanish (605) | 2019/10/12 | | ⭳ |
| 1283 | Japanese | → | English (1278) | Russian (1249) | Finnish (1050) | German (1025) | French (658) | 2019/10/12 | | ⭳ |
| 1086 | Hebrew | → | English (1086) | Esperanto (125) | Polish (120) | Russian (89) | French (83) | 2019/10/12 | | ⭳ |
| 1067 | Latin | → | English (974) | Portugeuse (430) | Spanish (375) | French (293) | Esperanto (199) | 2019/10/12 | | ⭳ |
| 480 | Central Dusun | → | English (401) | Japanese (45) | Coastal Kadazan (31) | 2019/10/12 | | ⭳ | ||
| 376 | Marathi | → | English (376) | Hindi (142) | 2019/10/12 | | ⭳ | |||
| 363 | Ukrainian | → | English (363) | French (28) | German (20) | Italian (17) | Spanish (15) | 2019/10/12 | | ⭳ |
| 224 | Polish | → | English (222) | Dutch (98) | German (30) | Ukrainian (27) | Russian (21) | 2019/10/12 | | ⭳ |
| 134 | Thai | → | English (87) | Esperanto (39) | German (38) | French (38) | Russian (32) | 2019/10/12 | | ⭳ |
| 112 | Catalan | → | English (111) | Spanish (41) | Ukrainian (31) | French (19) | Esperanto (17) | 2019/10/12 | ⭳ | |
| 60 | Chavacano | → | English (53) | 2019/10/12 | ⭳ | |||||
| 53 | Romanian | → | English (51) | Esperanto (51) | Dutch (50) | German (34) | Spanish (34) | 2019/10/12 | ⭳ | |
| 37 | Turkish | → | English (37) | German (13) | Esperanto (8) | Spanish (5) | Swedish (3) | 2019/10/12 | ⭳ | |
| 28 | Naga (Tangshang) | → | English (28) | 2019/10/12 | ⭳ |